
笔记 - SQL数据库的级联关系
type
status
date
slug
summary
tags
category
icon
password
Postgres 提供了一组有用的 Join 方法,用户可以执行这些方法来提取其数据中的逻辑关系。将讨论 6 种 Join 方法 - Inner Join、Left Join、Right Join、Full Outer Join、Cross Join 和 Self Join。
Inner Join 内联接
它返回两个表中的行,其中有一个匹配项,后跟一个指定的联接条件。仅生成在表 A 和表 B 中都匹配的记录集。

例如:
假设有两个表 - customers 和 orders:

我们需要已下订单的客户列表。为此,我们将使用 .
Inner Join主表是order,副表是customers,所以是
inter join customer on 
Left Join 左级联
它返回左表中的所有行和右表中的匹配行。如果没有匹配的行,则右表将返回 Null 值。
它从表 A 生成一组完整的记录,并在表 B 中生成匹配的记录。如果没有匹配项,则右侧将包含 null。
SELECT * FROM table1 LEFT JOIN table2 ON table1.column = table2.column;
例子:
假设有两个表 - employees 和 projects,并且我们希望获取分配到项目的所有员工名单,即使他们没有被分配到任何项目。

主表是员工
employees 副表谁 projects
Right Join 右级联
它返回右表中的所有行和左表中的匹配行。如果没有匹配的行,则左表将返回 Null 值。
它从表 B 生成一组完整的记录,并在表 A 中生成匹配的记录。如果没有匹配项,左侧将包含 null。
SELECT * FROM table1 RIGHT JOIN table2 ON table1.column = table2.column;
例子:
现在,假设我们想要获取所有项目及其分配到的员工的列表,即使没有员工分配给该项目。为此,我们可以使用 Right Join:

Full Outer Join 完全外部联接
它返回左侧和右侧表中都匹配的所有行。对于没有任何匹配项的列,将返回 Null 值。
它生成表 A 和表 B 中所有记录的集合,以及来自两侧的匹配记录(如果可用)。如果没有匹配项,则缺少的一侧将包含 null。
SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.column = table2.column;
例子:
假设,现在我们想要查看员工和项目的完整列表,以及未分配任何项目和未分配给任何员工的员工。在这种情况下,我们可以使用 Full Outer Join:

Cross Join 交叉联接
它返回两个表之间的笛卡尔乘法的结果。它将左表的每一行与右表的每一行组合在一起,并给出最终结果。它不需要任何条件。 (应用场景是什么?)
SELECT * FROM table1 CROSS JOIN table2;
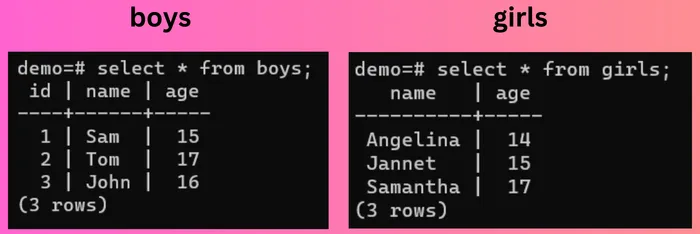
假设有两个表 - boys 和 girls:
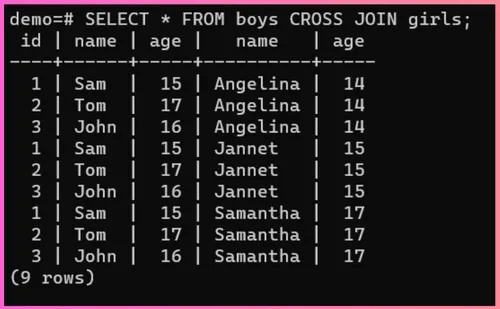
对于舞会之夜,我们想看看这份男孩和女孩名单可以组成多少对夫妇。为此,我们可以使用 Cross Join:
Self Join 自加入 自级联
它将表与自身联接并返回最终输出。Self joins 通常用于比较同一表中的行。
例
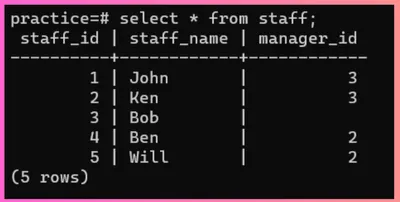
假设有一个表 employees,由员工 ID、员工姓名和他们的经理 ID 组成:
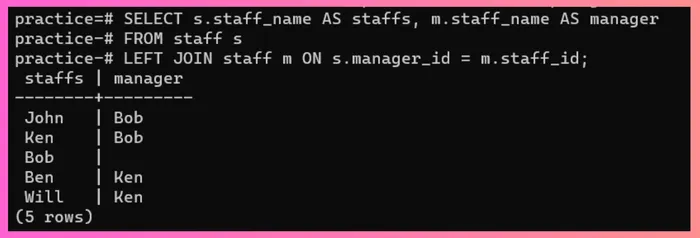
我们想获取员工名单以及他们各自经理的姓名。我们可以通过将 manager_id 与相应的 staff_id 进行匹配来获取 manager 名称。为此,我们将使用 Self Join:
笔记
<1>增加索引
如果某个大表的SELECT很频繁就需要加入索引(WHERE后的字段条件或者Join后的字段条件)
注意:索引不能随便乱加,如果一个表的delete或者update行为很频繁就不适合加很多索引。
<2>SQL语句尽可能少用内置函数,比如 LCASE,LEFT,LOWER,REPLACE,SUBSTRING,UCASE等
因为如果使用了内置函数,SQL语句就会跳过INDEX导致INDEX不起作用。
<3>如果使用EF实体开发,尽量少用ToLower()或者ToString()等这样的转换
因为如果使用以上,系统会自动将上面函数转为SQL语句的内置函数,导致INDEX不起作用,比如下面的.ToLower()就会自动转为LOWER(`w`.`VPLoginEmail`),同样ToString ()也会转为cast
<4>关于Like语句
如果能确定某个字段fieldsample的前几个字母请用fieldsample like ‘abc%’,不要用fieldsample like ‘%abc%’,前者继续走Index后者会导致Index失效。
<1>索引关联理解inner join 、left join
如果是inner join的话,一边有索引就可以了
如果是left join,主表可以不用索引,但另外张就要索引
<2>切记:小表驱动大表,给被驱动表建立索引
EXPLAIN语句分析出来的第一行的表即是驱动表
在以小表驱动大表的情况下,再给大表建立索引会大大提高执行速度
在join连接时哪个表是驱动表,哪个表是被驱动表:
1.当使用left join时,左表是驱动表,右表是被驱动表
2.当使用right join时,右表时驱动表,左表是驱动表
3.当使用join时,mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表
left join 原理是 左连接情况下左表全有,因此在右边创建索引,得到比较理想的效果
然后inner join是因为mysql自带得优化器能自动识别怎么去”找“更省时间
结论:left join:右边创建索引;right join:左表创建索引
<3>索引失效
场景:当使用关联查询(inner join、left join、right join)等进行查询时候,关联条件都已建立索引,但查看执行计划发现并未走索引。
原因:两表字段的字符集不相同导致关联查询索引失效
解决方案:
1.修改表字段字符集类型,保证字符集一致
2.使用convert()函数,保证关联的索引字段 转换后两边字符集一致
<4>索引在关联查询中的作用
MySQL执行关联查询的策略简单地说,先从一个表循环取出单条数据,然后再循环到下一个表中寻找匹配的行,然后再下一个表,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。

根据上述内容,第一张表很重要。但关联顺序并不是按照SQL语句中的顺序。在执行关联查询的时候,关联查询优化器通过评估不同顺序时的成本,选择一个代价最小的关联顺序。当然如果需要,可以使用STRAIGHT_JOIN关键字人工指定关联顺序。
所以,多表关联查询,比如三表关联,执行过程大概是,关联查询优化器选择其中一个查询成本最小的表,一般是扫描行数最少,然后根据关联字段关联后面第二、第三张表。可见如果第二、第三张表上有索引,就能大幅提高性能。优化关联查询,确保ON或者USING子句上的列有索引。在创建索引的时候就要考虑到关联顺序。优化器的关联顺序中最前面的表不需要在关联列上建索引,只需在关联顺序中的第二个及以后表的相应列上建索引。
可见,在关联查询中,第一张表以后的多张表的关联字段上的索引,可以同时起作用。
此外注意,要确保任何group by和order by中的表达式只涉及到一个表中的列,这样mysql才有可能使用索引来优化这个过程。